LLMs vs. Humans: The Scoring Gap
GENIUS Center Research Hub proudly highlights a new study led by Xuansheng Wu (Ph.D. student, School of Computing, University of Georgia) in 2025. This research uncovers how Large Language Models (LLMs) differ from human graders in evaluating student responses, offering insights into why AI-based scoring systems can sometimes miss logical nuances. Wu’s work points to the importance of well-crafted analytic rubrics to bridge this alignment gap between humans and AI, ultimately enhancing the accuracy of automated scoring.

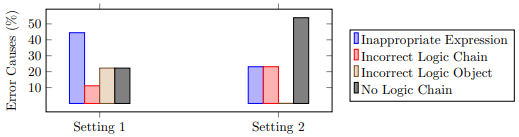
| While LLMs show potential for automatic scoring, a notable alignment gap exists in their scoring reasoning process compared to humans. According to Wu et al., LLMs often do not create grading rules, or analytic rubrics, that fully match those crafted by human educators. Contrary to traditional assumptions in automatic scoring, the study found that giving LLMs examples of student answers with assigned grades can mislead the LLMs into focusing on keywords rather than evaluating the underlying logic of the responses. Importantly, guiding the LLMs with high-quality analytic rubrics, particularly those designed to reflect human grading logic, can enhance the scoring accuracy of LLMs. |